Problem: Current large multimodal models (LMMs) struggle to bridge the gap between low-level visual perception—focusing on shapes, sizes and layouts—and high-level language reasoning involving semantics, events and logic. This limitation becomes evident in tasks requiring precise visual perception, such as comparing geometric properties or solving visual algorithmic reasoning problems. To study this failure mode, we focus on an important visual domain: vector graphics—images composed purely of 2D objects and shapes, which are prevalent in various LMM-based agent tasks in web, visual design, and OS environments.
Key research questions: (1) how can we enable precise visual perception in LMMs? and (2) how can we facilitate high-level reasoning based on such low-level perceptions?
Method: To accurately capture low-level visual details, we utilize Scalable Vector Graphics (SVG) for precise encoding of visual scenes. However, SVGs are not readily interpretable by LLMs or LMMs in a zero-shot manner. To address this challenge, we propose the Visually Descriptive Language Model (VDLM), which introduces an intermediate textual representation called Primal Visual Description (PVD). PVD translates SVGs into a text-based abstraction comprising primitive attributes (e.g., shape, position, measurement) along with their corresponding values. This abstraction is more structured and closer to natural language, allowing for direct interpretation by foundation models for zero-shot generalization to different reasoning tasks
Performance: Without any human-annotated data, empirical results demonstrate that VDLM leads to significant improvements in state-of-the-art LMMs, such as GPT-4o, across various low-level multimodal perception and reasoning tasks on vector graphics. VDLM also offers better interpretability due to its disentangled perception and reasoning processes.
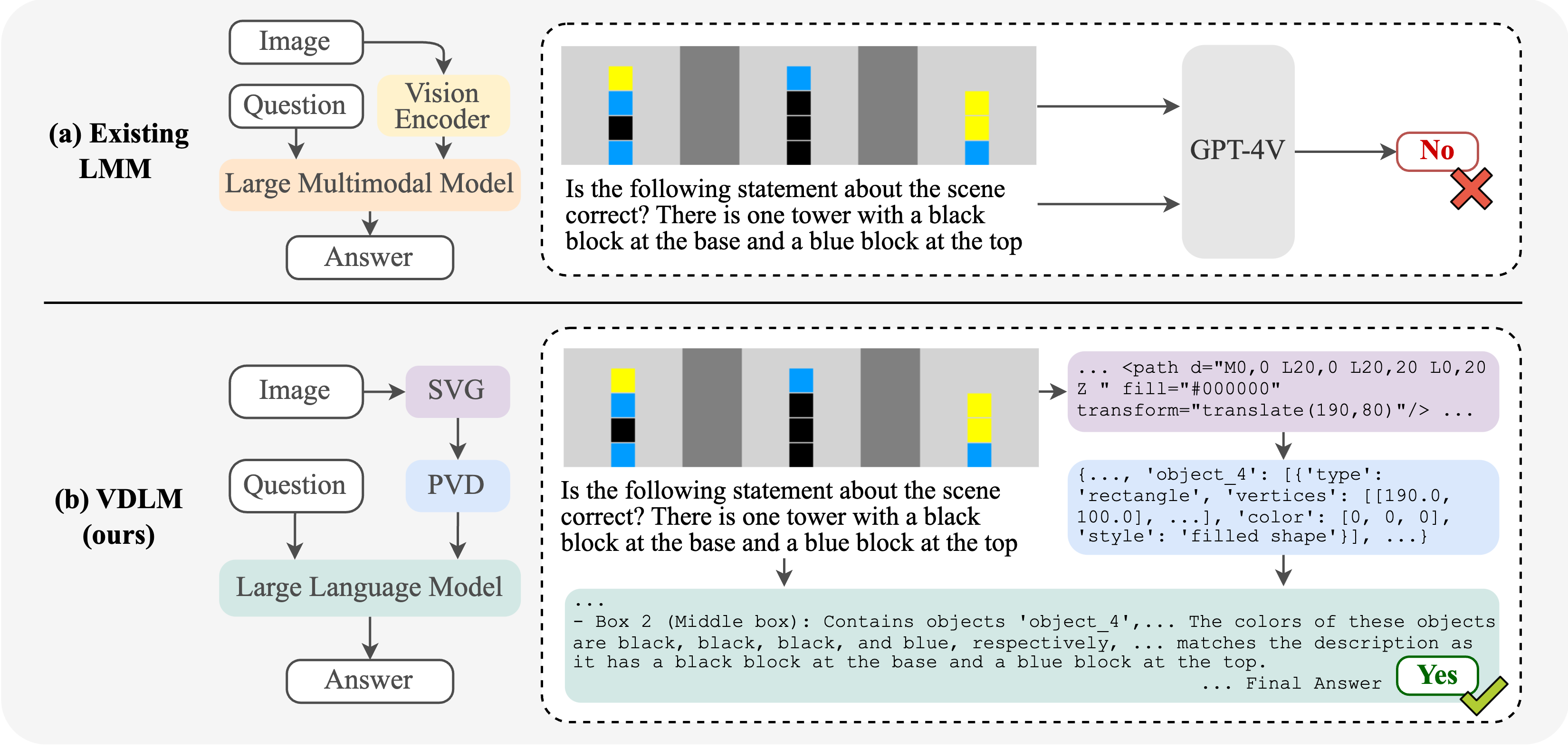
We leverage a rule-based image-to-SVG parsing algorithm, VTracer, for converting any image into SVG without learning. This enables us to obtain an accurate initial perception of the input vector graphic images. However, we observe two key challenges when working with raw SVG representation. First, off-the-shelf foundation models, e.g., GPT-4, have limited zero-shot reasoning ability on SVG representation. Second, fine-tuning on task-specific ⟨SVG, question, answer⟩ pairs limits generalization to unseen tasks and domains. We discuss our approach for extracting intermediate representations below.

We propose Primal Visual Description (PVD), a higher-level abstraction that transforms low-level SVG paths to more structured primitives required for reasoning. PVD is a text-based visual description that consists of a set of primitive geometry objects, e.g., circles, line segments. Each PVD element contains the primitives' attributes (e.g., color, shape, position, size) with corresponding predicted values (e.g., blue, circle, pixel coordinates of the center, length of the radius). See Figure 2 for the ontology we defined. Notably, unlike raw SVG, PVD is directly interpretable by state-of-the-art LLMs and LMMs, enabling zero-shot reasoning on downstream tasks.
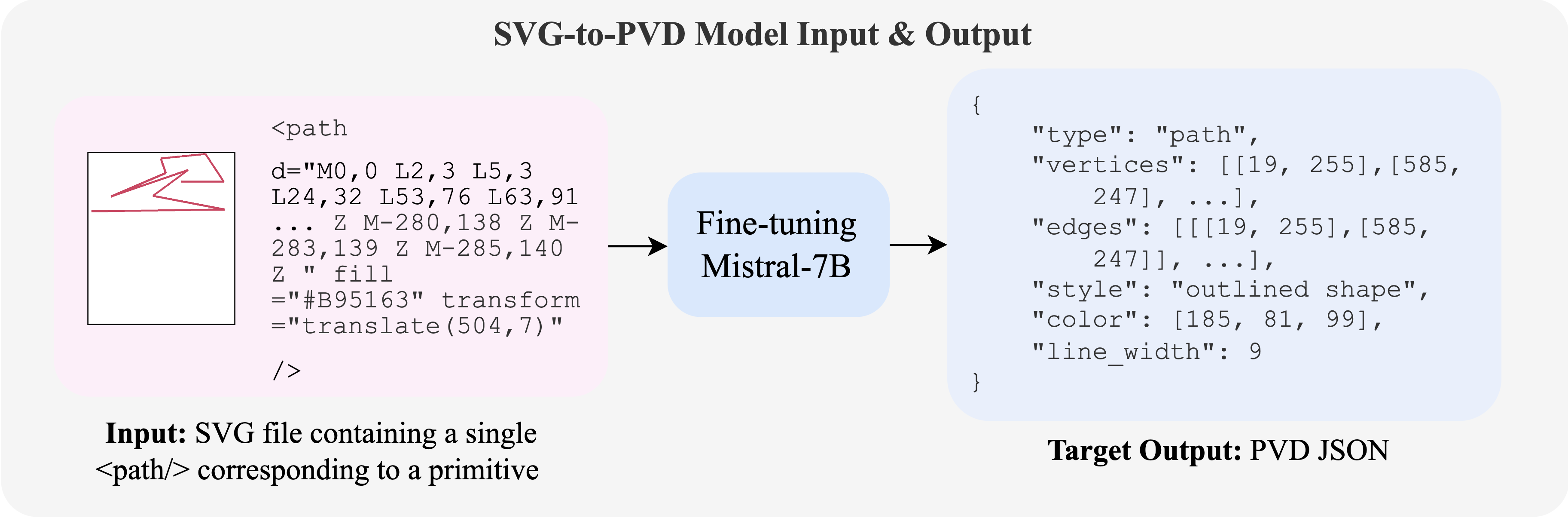
Since SVG is text-based, we can effectively learn a SVG-to-PVD model by fine-tuning a pretrained language model (Mistral-7B-v0.1). To obtain the training data, we develop a data generator leveraging PIL.ImageDraw and VTracer, which creates a large-scale ⟨SVG, PVD⟩ paired dataset without any human annotation. See Figure 3 above on an input/output example. During inference, as shown in the Maze Solving example video, we first decompose the input image into single SVG paths and then individually feed them into the SVG-to-PVD model.
Given an unseen task, we first use our visual perception modules, as aformentioned, to generate a precise PVD perception of the input vector graphics. We input the perception result into the prompt along with the task-specific instructions, and then feed it into an inference-only LLM or LMM reasoner. We explore two variants of VDLM, namely VDLM-txt and VDLM-mm, depending on the type of reasoner applied. VDLM-txt leverages a text-only LLM as the reasoner and solely uses PVD to represent the visual information, whereas VDLM-mm leverages an multimodal LMM as the reasoner, which can additionally take the original image as visual input. An example of the full input prompt and GPT-4 response of the 2×2 Maze Solving example can be viewed below.




We construct an evaluation benchmark that comprises 9 tasks which cover important aspects of low-level visual perception and vision-language reasoning, including measurements, spatial relations, counting, logical reasoning, and complex reasoning problems. See Figure 4 for the task examples. We additionally include a set of high-level tasks from VGBench to investigate the impact of VDLM on semantic-centric reasoning, which rarely require precise perception of the locations and measurements of the primitives.
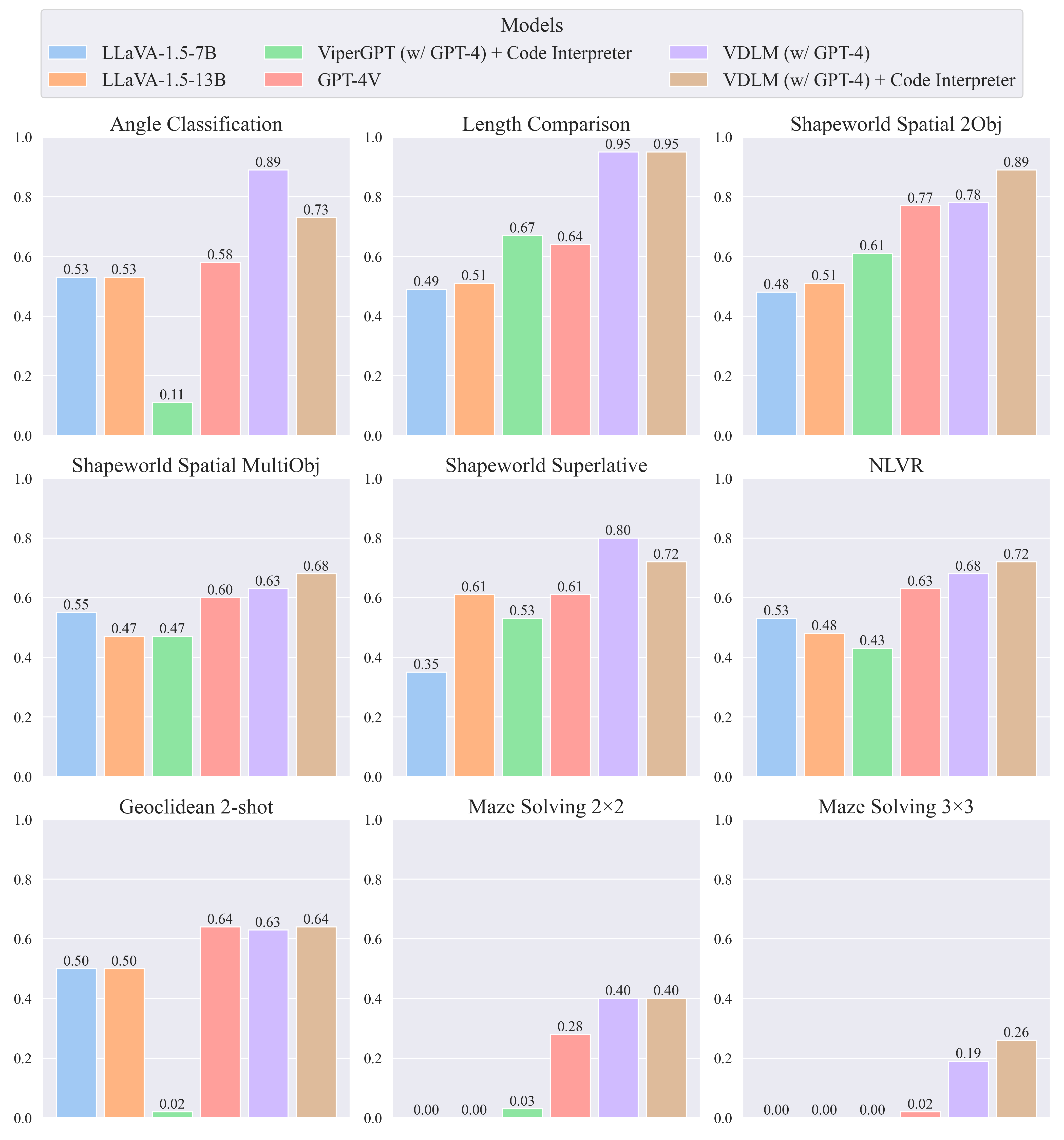
VDLM-txt, even without access to the original image, outperforms strong LMMs such as GPT-4V, highlighting the efficacy of the intermediate PVD representation for precise low-level perception and reasoning. VDLM-mm significantly improves state-of-the-art LMMs, such as GPT-4o, on low-level reasoning tasks, while preserving their capabilities in high-level reasoning. We observe that G-LLaVA, a model demonstrating strong performance on geometric problems, such as MathVista, still struggles with understanding basic lines and angles, which are prerequisites for solving geometric math problems. This indicates that the QA performance on complex math problems does not necessarily reflect a faithful understanding of low-level visual concepts. VDLM also outperforms previous visual programming methods, i.e., ViperGPT, indicating that these models are limited by the capability of the vision-language processors, such as GLIP and BLIP2, especially in processing low-level primitives such as angles and shapes.
Although the PVD representation has already shown significant promise with a limited ontology and a fully synthesized training dataset, it is not yet perfect when generalizing to diverse domains. In certain tasks, such as Shapeworld Spatial Reasoning, VDLM-mm brings negative impact to GPT-4o. The reason for this lies in the imperfect perception results from the SVG-to-PVD model. Future directions include building a more general PVD model that has a broader coverage of 2D concepts and can be extended to 3D and natural images. For detailed results and analysis, please refer to our paper.
💻 Code: VDLM Code
🍉 Demo (Jupyter Notebook): VDLM Demo
🤗 Pretrained SVG-to-PVD Model: PVD-160k-Mistral-7b
🤗 SVG-to-PVD Dataset: PVD-160K
@article{wang2024vdlm,
title={Visually Descriptive Language Model for Vector Graphics Reasoning},
author={Wang, Zhenhailong and Hsu, Joy and Wang, Xingyao and Huang, Kuan-Hao and Li, Manling and Wu, Jiajun and Ji, Heng},
journal={arXiv preprint arXiv:2404.06479},
year={2024}
}
 Visually Descriptive Language Model for Vector Graphics Reasoning
Visually Descriptive Language Model for Vector Graphics Reasoning